To understand the behavior of Semji's content extractor
You have created a Draft from existing content (Updated Content) and you see that Semji has not retrieved all the editorial content?
Table of contents:
Understanding the extractor
How do I retrieve my online content in the Semji editor?
Complete the editorial text using copy and paste
|
Free trial |
Custom Legacy |
Basic |
Business |
Unlimited |
|
❌ |
✅ |
✅ |
✅ |
✅ |
Understanding the extractor
IMPORTANT: Semji uses a content extractor robot. This extractor is configured to adapt to the majority of our users' site structures. However, our extractor may not be able to retrieve the editorial content of your pages according to your templates.
On most CMS (your site manager), with classic page layouts, our extractor efficiently identifies the editorial content of the page. It imports Hn title tags (H1, H2, H3...), text paragraphs, internal links within paragraphs, as well as the formatting (bold, italic...) you've used.
Our extractor is configured to exclude elements such as menus, footers, sidebar modules... that are not covered by Semji's optimization recommendations.
When faced with more complex templates, layouts or page layouts, the extracted content may be partial. This may be the case on pages such as product sheets, or service pages made up of several distinct blocks, with text located after several scrolls, for example.
You should be aware that some sites block access to our robots, making it difficult to read the content. Certain UX display choices can also limit text retrieval within the HTML code of your page.
It's also important to note that the Semji Bot does not execute Javascript code within your pages. This means that if your content is exclusively displayed after Javascript execution and is not present in the DOM at loading, the extractor may only extract it partially or not at all.
How do I retrieve my online content in the Semji editor?
This automatic recovery, which uses the default extractor, takes place when you transform existing content into a draft, i.e. an editable version of your content.
You can easily see whether you're on the online version of uneditable content or on the draft, editable version, thanks to the pictograms at the top of your menu bar.
Click on the pencil icon to transform visible online content into editable content and create a draft in Semji.

Semji then invites you to start optimizing your content: "Start optimization". By clicking on this button, you create the draft and launch the automatic retrieval of your text. Semji asks you to wait a few seconds, displaying the message "Content being retrieved". During this time, your content and its formatting are retrieved and pasted into the editor.
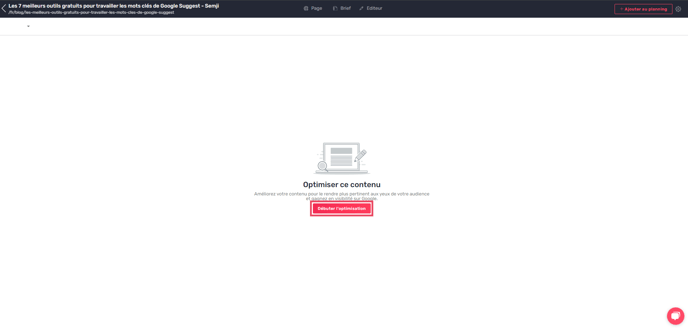
Please note: This action doesn't spend any analysis credit. It simply retrieves all your content to save you time. The analysis credit will be spent once you've selected your keyword and run the keyword analysis.
Once you've retrieved your content, you can view it in the Semji editor. Now you can start optimizing your content.
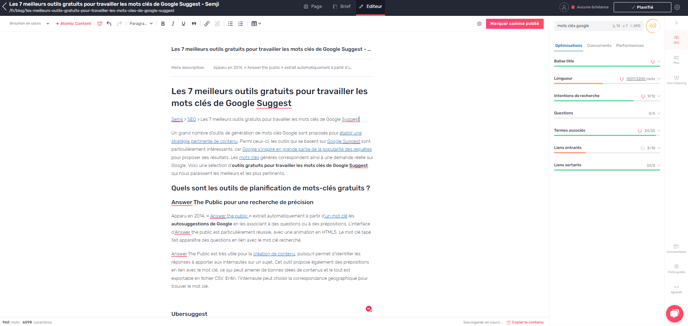
Complete the editorial text using copy and paste
If you notice any discrepancies in the retrieval of your content, please contact your CSM or our Chat to let us know. We will then be able to correct your extractor settings.
Until your problem has been resolved, we recommend that you copy and paste the missing text into the editor to continue your optimization work.